Probably one of the best things about the internet is the culture of shared knowledge it has promoted. I can’t count how many times I have searched Stackoverflow to understand a Python error or to help me understand why I am getting unexpected results from a model I am training. You can pretty much Google anything and within 5-10 minutes learn something new. I have always wondered how these algorithms can be robust enough to answer questions accurately, especially when taking into account typos and grammatical errors. For my final project at Metis, I decided to build a model that could match questions based on semantic similarity. The scope of this project will be to train a model on question pairs labeled as having the same intent or not in order to build a Slack bot which a user can ask any question, and the bot will respond with an answer that is the most similar to that of a previously answered question. Let’s get started!
Methodology
First, I needed a data set to train a classification model to detect whether or not a pair of questions had the same intent. I utilized a data set provided by Quora and hosted on Kaggle. The data set contained 400,000 pairs of questions which were manually labeled as having the same intent or not. The questions are all real questions posted on Quora with a diverse set of topics, and spelling and grammar mistakes.
Next, I cleaned and lemmatized the questions using the spaCy model, en_core_web_lg, and engineered features. The full details of the features can be found in the Feature Engineering section.
Next, I trained Random Forrest and Gradient Boosted models. The Gradient Boosted model was the xgboost implementation. I hyper tuned both the best Random Forrest and Gradient Boosted model, and ultimately selected the Gradient Boosted model based on average validation AUC in 3-fold cross validation.
Finally, I utilized a question and answer data set from MS MARCO as the basis for all known questions and answers in the Slack bot. The Slack bot was developed utilizing Flask to handle the HTTP requests from from the Slack API, and ngrok to expose the Flask server to the Slack API server.
Feature Engineering
I engineered two sets of features. One set focused on the pair of questions, and the other set focused on each individual question.
N-gram similarity
The n-gram similarity feature is a set similarity comparison of the n-grams from the pair of questions. I considered single, bi-, and tri-grams. The feature is calculated as,
Where is the set of n-grams from the first question, and is the set of n-grams from the second question.
Distance features
I utilized GloVe word embeddings provided by the spaCy en_core_web_lg model to calculate distance features for each question. The minimum, maximum, and average distance between all words in a question were calculated. The set of features was calculated on the individual question, rather than the pair of questions.
Example
Let’s consider these two questions.
- How do I learn machine learning?
- How do I become an astronaut?
Each word in each question can be mapped to a word embedding, and then distances calculated. Euclidean, cosine, and manhattan distances were calculated, and the comparison of the two questions is below.
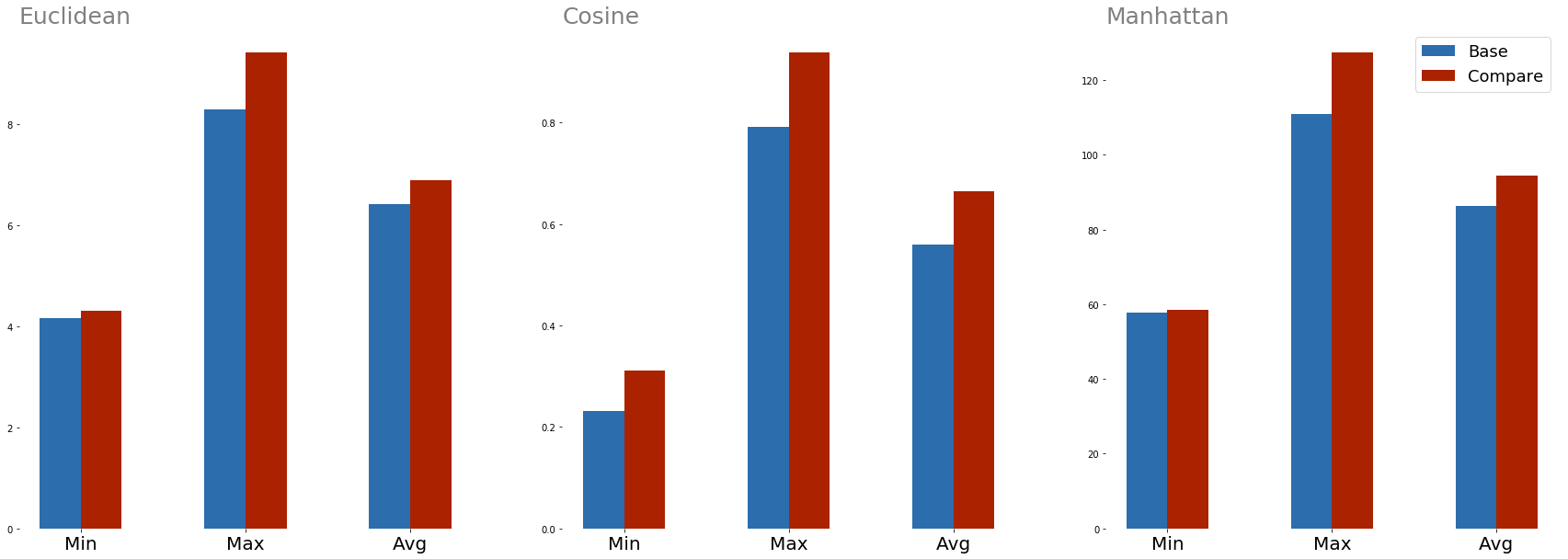 Figure 1: Comparing distances between questions without the same intent
Figure 1: Comparing distances between questions without the same intent
Now we can add a third question, unseen by the model, and see how a classification model can start to learn semantic similarities between two questions. The third question is,
- What steps should I follow to learn machine learning?
The updated graph is now below,
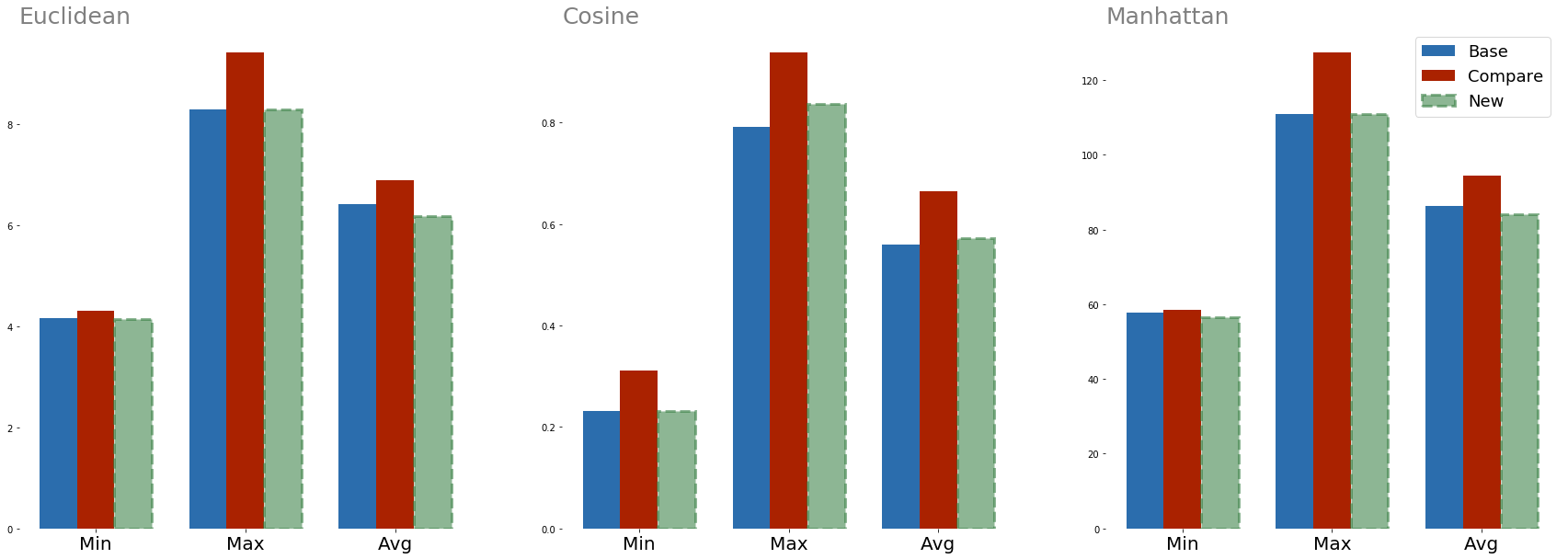 Figure 2: Comparing distances between questions with the same intent
Figure 2: Comparing distances between questions with the same intent
Model Selection and Results
I trained many models with different features. A summary of those models can be seen below.
| Avg. AUC | Avg. F1 | |
|---|---|---|
| xgb_hypertuned | 0.885 | 0.729 |
| xgb_hypertuned_dup_features | 0.874 | 0.713 |
| rf_feat_eng_model_lemma_clean | 0.868 | 0.706 |
| ensemble_rf_xgb | 0.863 | 0.703 |
| xgb_feat_eng_incl_nums | 0.852 | 0.692 |
| feat_eng_model_lemma_clean | 0.847 | 0.684 |
| feat_eng_model_lemma_fix | 0.822 | 0.642 |
| feat_eng_model | 0.821 | 0.64 |
| ensemble_rf_xgb_cos_sim | 0.82 | 0.636 |
| lstm_Bidrectional | 0.804 | 0.632 |
| lstm_dropout_50 | 0.802 | 0.639 |
| lstm_LEMMA_dropout_20_lstm_layer_DO_20 | 0.802 | 0.624 |
| lstm_mvp | 0.801 | 0.637 |
| cos_sim_tfidf_model | 0.8 | 0.599 |
| lstm_LEMMA_SW_dropout_20_lstm_layer_DO_20 | 0.794 | 0.623 |
| lstm_dropout_50_lstm_layer_DO_50 | 0.786 | 0.618 |
| lstm_CNN | 0.777 | 0.607 |
| lstm_dropout50_dense50_BatchNorm | 0.772 | 0.574 |
| cos_sim_model | 0.747 | 0.532 |
| mvp (tf-idf, nmf(5), xgboost) | 0.741 | 0.487 |
| mvp (+ lemma) | 0.738 | 0.485 |
Ultimately, Random Forrest and Gradient Boosted models with the features described within this document performed the best, and both were hyper-tuned. I hyper-tuned utilizing BayesSearchCV from skopt, and utilized validation AUC to select the xgboost labeled as xgb_hypertuned_dup_features in the above table. The ROC curve of the held-out test data is below, and the model scored an 0.88 AUC on the test data, thus a little better than the avg validation AUC.
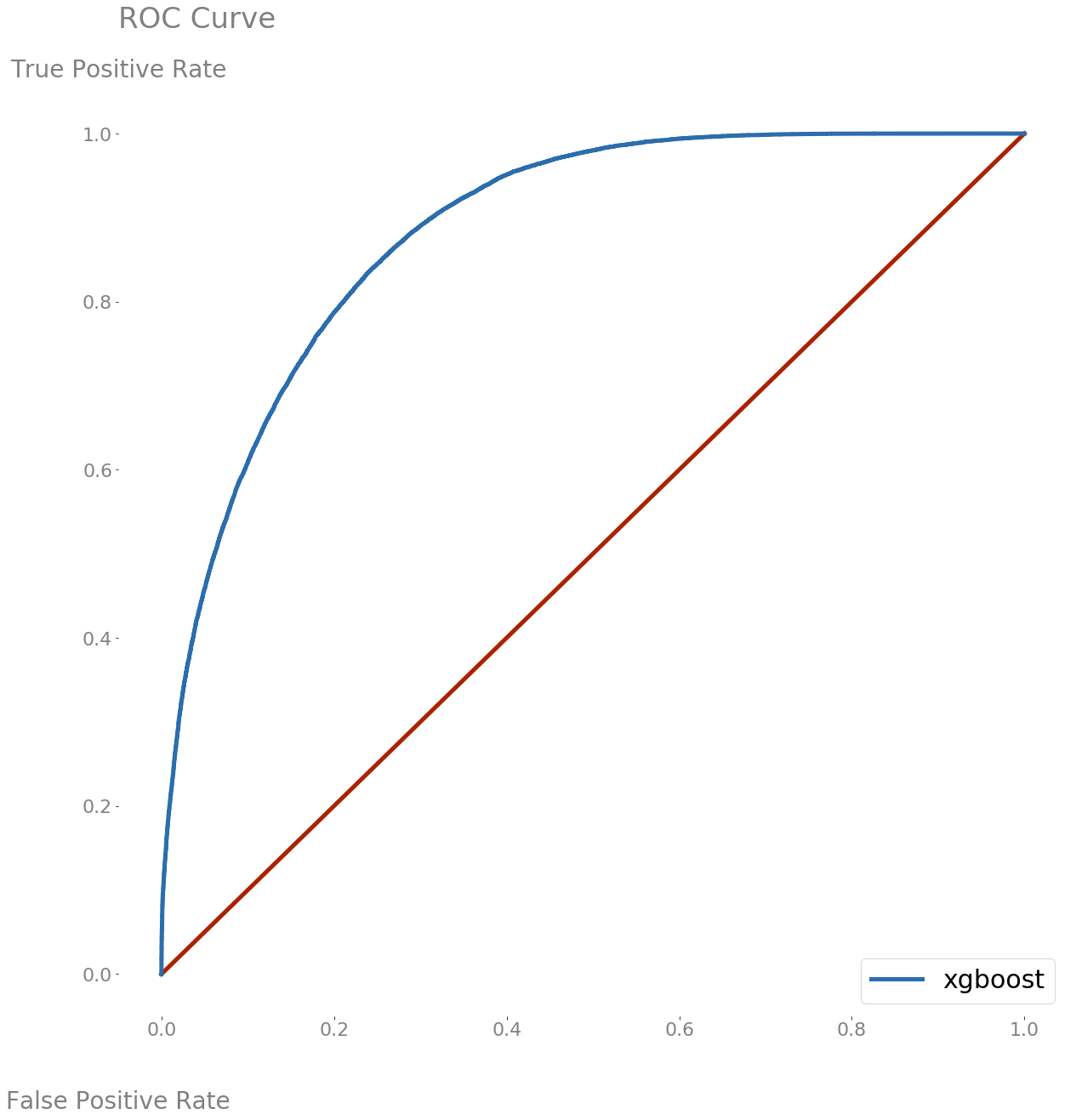 Figure 3: ROC Curve of the test data
Figure 3: ROC Curve of the test data
JasonBot (Q&A Slack bot)
I applied the trained model to a question and answer Slack bot application. The underlying assumption for the application is that some historical questions have already been asked and answered. This data originated from MS MARCO. The Slack bot was deployed on the Metis Community Channel and the /q command was enabled to receive any question and respond with the top 3 answers. In addition to the answers, the similar question and confidence level are returned. A demo of the bot is below.
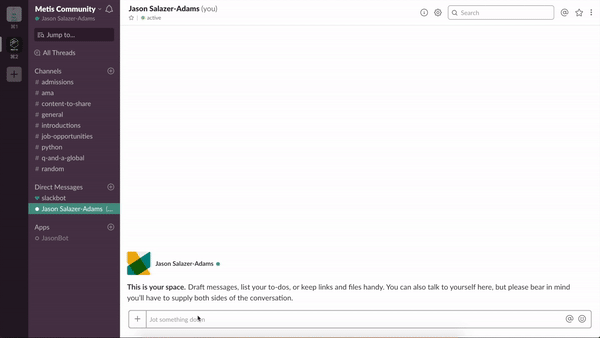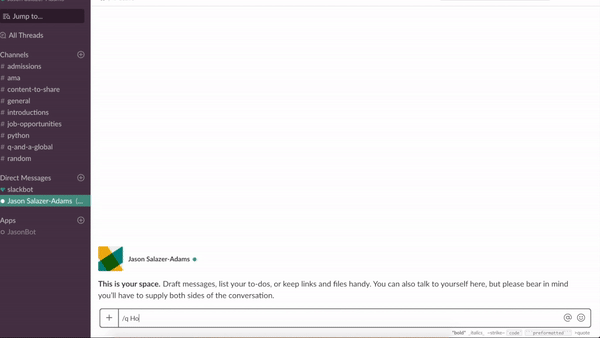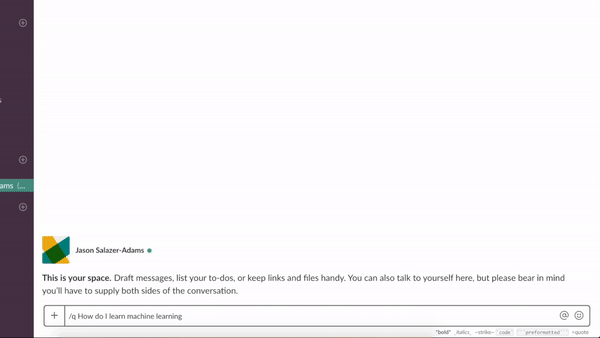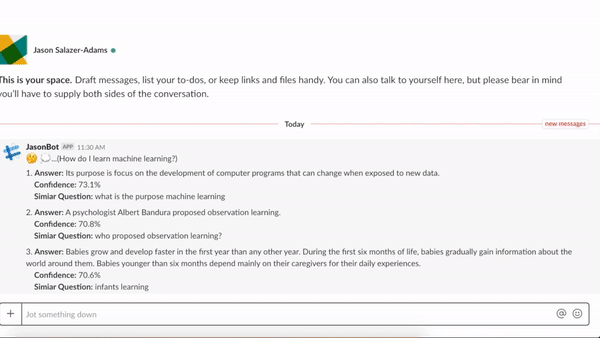 Figure 4: Demo of the Slack bot
Figure 4: Demo of the Slack bot
Future Work
Here are some areas where my model can be enhanced further,
- Utilize different word embeddings to see if different embeddings could enhance the distance feature set.
- Apply a Siamese network architecture utilizing LSTM to classify whether or not two Quora questions have the same intent.
- Change the Slack bot paradigm from a question and answer lookup to text generation utilizing the Wikipedia corpus.